
티스토리 뷰
엑셀 파일 정확하게는 CSV파일을 읽어서 간단하게 파이썬 데이터 구조로 만드는 방법이 필요한데
pandas로 아주 간단히 가능하다.
샘플로 얼굴의 landmark 정보 데이터를 사용했다. 다음 링크에서 얼굴 이미지와 연습용 csv파일을 다운받을 수 있다.
https://download.pytorch.org/tutorial/faces.zip
pandas 라이브러리 불러오기
먼저 다음과 같이 pandas 라이브러리를 불러온다.
import pandas as pd
파일 읽기
파일위치 폴더를 포함한 csv파일이름을 파라미터로 read_csv 함수에 입력하여 데이터를 간단하게 읽어 올 수 있다.
landmarks = pd.read_csv('faces/face_landmarks.csv')원래 csv파일을 읽어 보면 다음과 같다.
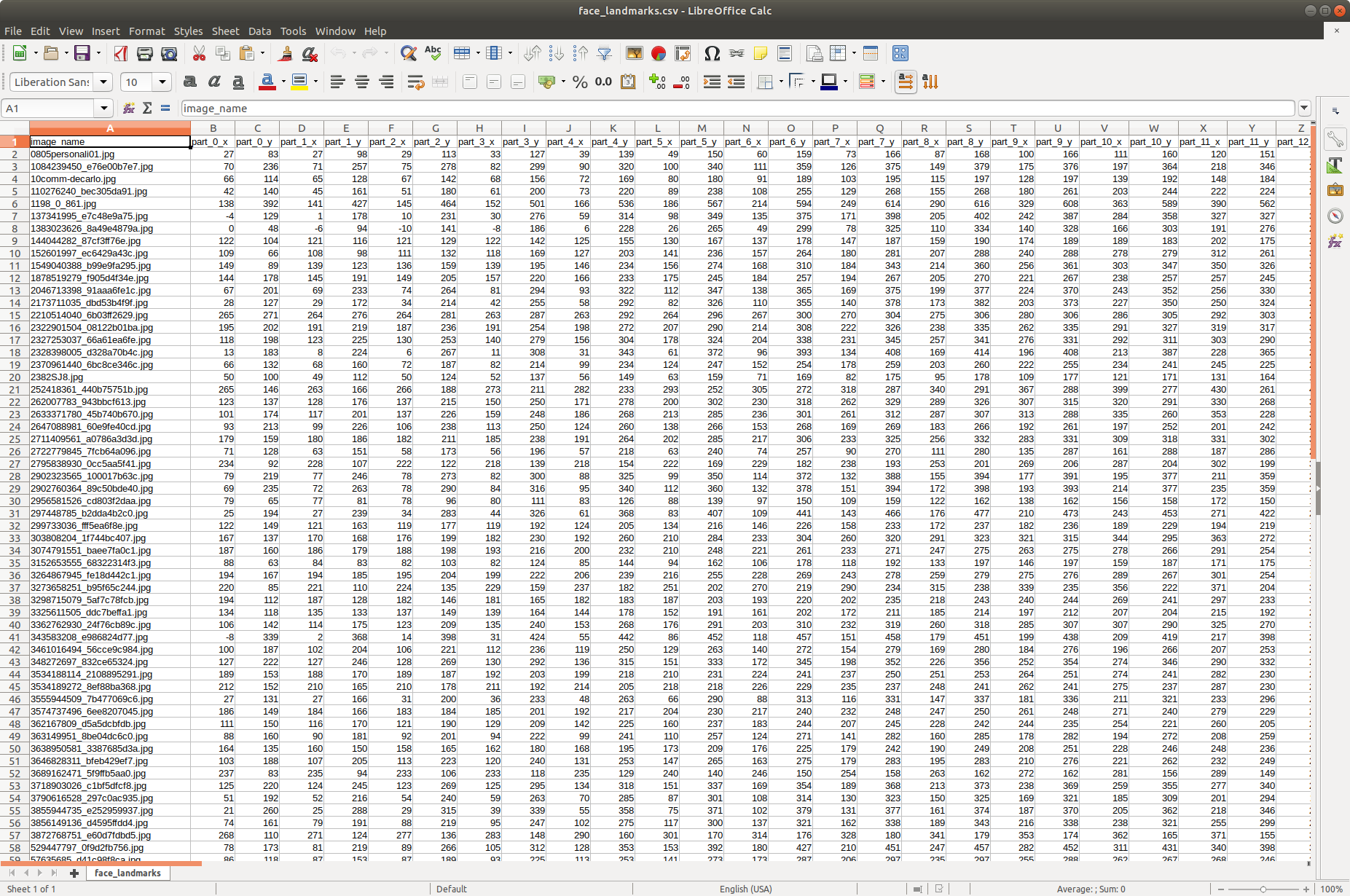
가장 첫번째 행은 각 열의 카테고리를 나타내고 있으며 다음 행부터 데이터가 들어가 있다. 간단하게 첫번째 열은 이미지 파일 이름이 들어 있고 나머지는 각 얼굴 이미지에 대한 특징점 데이터들의 좌표들이다.
데이터 확인해보기
입력된 데이터를 확인해 보면 다음과 같다.
landmarks
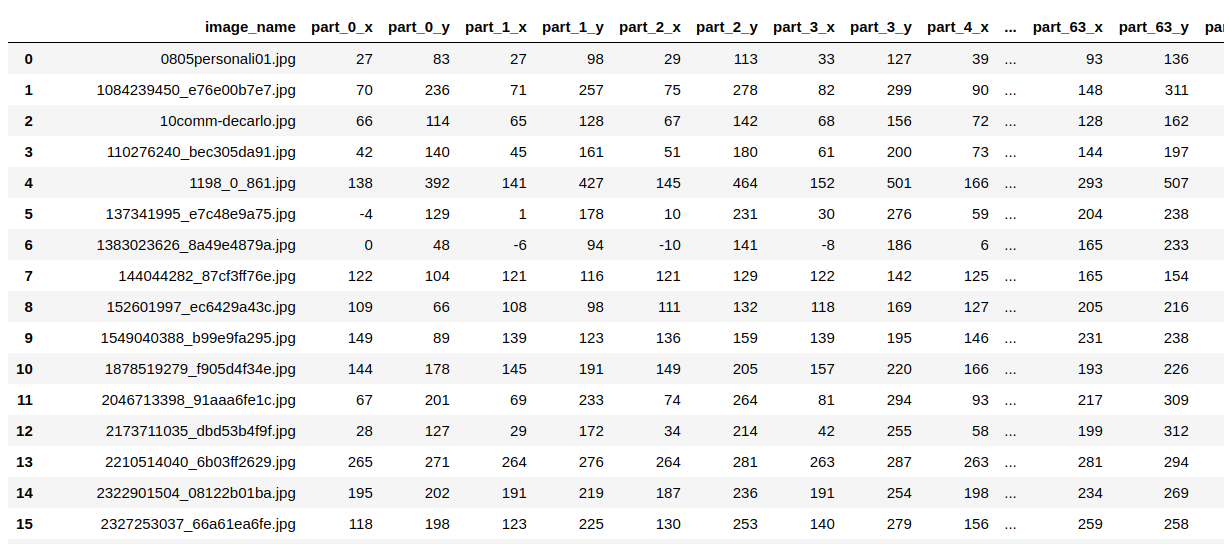
csv파일을 엑셀 프로그램에서 읽었을 때 구조가 그대로 들어가 있는 것을 알 수 있다.
loc로 데이터 슬라이싱하기
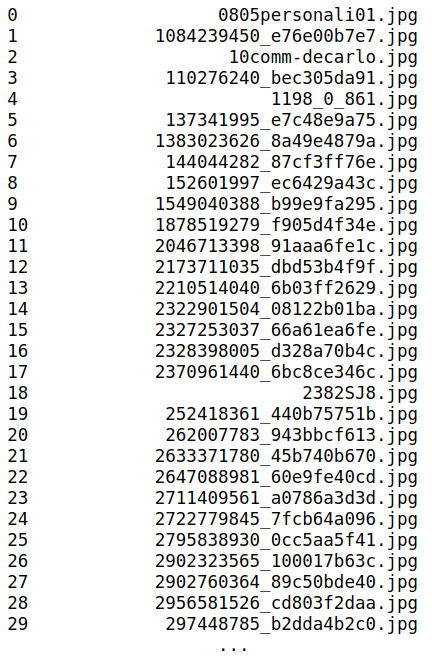
loc는 카테고리 이름으로 데이터를 슬라이싱하는 명령어이다. 다음과 같이 image_name 카테고리 이름을 이용해 이미지 파일들만 따로 뽑을 수 있다.
landmarks.loc[:,'image_name']다음과 같이 이미지 파일명만 따로 뽑을 수 있다.
as_matrix() / values
사실 이 데이터는 pandas에서 쓰는 데이터프레임 형식으로 파이썬에서 그대로 쓸수 없다. 여기에 간단히 as_matrix()를 추가하여 배열 데이터 구조로 변형이 가능하다. 이후에 as_matrix()는 사라진다고 주의 메시지를 보니 values를 사용해도 된다.
print(landmarks.loc[:,'image_name'].values)
['0805personali01.jpg' '1084239450_e76e00b7e7.jpg' '10comm-decarlo.jpg'
'110276240_bec305da91.jpg' '1198_0_861.jpg' '137341995_e7c48e9a75.jpg'
'1383023626_8a49e4879a.jpg' '144044282_87cf3ff76e.jpg'
'152601997_ec6429a43c.jpg' '1549040388_b99e9fa295.jpg'
'1878519279_f905d4f34e.jpg' '2046713398_91aaa6fe1c.jpg'
'2173711035_dbd53b4f9f.jpg' '2210514040_6b03ff2629.jpg'
'2322901504_08122b01ba.jpg' '2327253037_66a61ea6fe.jpg'
'2328398005_d328a70b4c.jpg' '2370961440_6bc8ce346c.jpg' '2382SJ8.jpg'
'252418361_440b75751b.jpg' '262007783_943bbcf613.jpg'
'2633371780_45b740b670.jpg' '2647088981_60e9fe40cd.jpg'
'2711409561_a0786a3d3d.jpg' '2722779845_7fcb64a096.jpg'
'2795838930_0cc5aa5f41.jpg' '2902323565_100017b63c.jpg'
'2902760364_89c50bde40.jpg' '2956581526_cd803f2daa.jpg'
'297448785_b2dda4b2c0.jpg' '299733036_fff5ea6f8e.jpg'
'303808204_1f744bc407.jpg' '3074791551_baee7fa0c1.jpg'
'3152653555_68322314f3.jpg' '3264867945_fe18d442c1.jpg'
'3273658251_b95f65c244.jpg' '3298715079_5af7c78fcb.jpg'
'3325611505_ddc7beffa1.jpg' '3362762930_24f76cb89c.jpg'
'343583208_e986824d77.jpg' '3461016494_56cce9c984.jpg'
'348272697_832ce65324.jpg' '3534188114_2108895291.jpg'
'3534189272_8ef88ba368.jpg' '3555944509_7b477069c6.jpg'
'3574737496_6ee8207045.jpg' '362167809_d5a5dcbfdb.jpg'
'363149951_8be04dc6c0.jpg' '3638950581_3387685d3a.jpg'
'3646828311_bfeb429ef7.jpg' '3689162471_5f9ffb5aa0.jpg'
'3718903026_c1bf5dfcf8.jpg' '3790616528_297c0ac935.jpg'
'3855944735_e252959937.jpg' '3856149136_d4595ffdd4.jpg'
'3872768751_e60d7fdbd5.jpg' '529447797_0f9d2fb756.jpg'
'57635685_d41c98f8ca.jpg' '809285949_6889026b53.jpg'
'92053278_be61a225d2.jpg' '96063776_bdb3617b64.jpg'
'97308305_4b737d0873.jpg' 'britney-bald.jpg' 'deeny.peggy.jpg'
'matt-mathes.jpg' 'person-7.jpg' 'person.jpg'
'person_TjahjonoDGondhowiardjo.jpg' 'personalpic.jpg']
iloc로 데이터 슬라이싱하기
iloc는 인덱스 번호로 데이터를 골라내는 것으로 배열 처럼 쉽게 사용할 수 있어서 개인적으로 더 많이 쓰는 것 같다.
앞에서 image_name 카테고리로 데이터 열을 골라낸 것을 인덱스 번호로 다음과 같이 사용해서 같은 데이터를 구할 수 있다.
print(landmarks.iloc[:,0].values)
['0805personali01.jpg' '1084239450_e76e00b7e7.jpg' '10comm-decarlo.jpg'
'110276240_bec305da91.jpg' '1198_0_861.jpg' '137341995_e7c48e9a75.jpg'
'1383023626_8a49e4879a.jpg' '144044282_87cf3ff76e.jpg'
'152601997_ec6429a43c.jpg' '1549040388_b99e9fa295.jpg'
'1878519279_f905d4f34e.jpg' '2046713398_91aaa6fe1c.jpg'
'2173711035_dbd53b4f9f.jpg' '2210514040_6b03ff2629.jpg'
'2322901504_08122b01ba.jpg' '2327253037_66a61ea6fe.jpg'
'2328398005_d328a70b4c.jpg' '2370961440_6bc8ce346c.jpg' '2382SJ8.jpg'
'252418361_440b75751b.jpg' '262007783_943bbcf613.jpg'
'2633371780_45b740b670.jpg' '2647088981_60e9fe40cd.jpg'
'2711409561_a0786a3d3d.jpg' '2722779845_7fcb64a096.jpg'
'2795838930_0cc5aa5f41.jpg' '2902323565_100017b63c.jpg'
'2902760364_89c50bde40.jpg' '2956581526_cd803f2daa.jpg'
'297448785_b2dda4b2c0.jpg' '299733036_fff5ea6f8e.jpg'
'303808204_1f744bc407.jpg' '3074791551_baee7fa0c1.jpg'
'3152653555_68322314f3.jpg' '3264867945_fe18d442c1.jpg'
'3273658251_b95f65c244.jpg' '3298715079_5af7c78fcb.jpg'
'3325611505_ddc7beffa1.jpg' '3362762930_24f76cb89c.jpg'
'343583208_e986824d77.jpg' '3461016494_56cce9c984.jpg'
'348272697_832ce65324.jpg' '3534188114_2108895291.jpg'
'3534189272_8ef88ba368.jpg' '3555944509_7b477069c6.jpg'
'3574737496_6ee8207045.jpg' '362167809_d5a5dcbfdb.jpg'
'363149951_8be04dc6c0.jpg' '3638950581_3387685d3a.jpg'
'3646828311_bfeb429ef7.jpg' '3689162471_5f9ffb5aa0.jpg'
'3718903026_c1bf5dfcf8.jpg' '3790616528_297c0ac935.jpg'
'3855944735_e252959937.jpg' '3856149136_d4595ffdd4.jpg'
'3872768751_e60d7fdbd5.jpg' '529447797_0f9d2fb756.jpg'
'57635685_d41c98f8ca.jpg' '809285949_6889026b53.jpg'
'92053278_be61a225d2.jpg' '96063776_bdb3617b64.jpg'
'97308305_4b737d0873.jpg' 'britney-bald.jpg' 'deeny.peggy.jpg'
'matt-mathes.jpg' 'person-7.jpg' 'person.jpg'
'person_TjahjonoDGondhowiardjo.jpg' 'personalpic.jpg']
배열에서 사용하는 : 같은 표현법을 사용하여 특정한 행을 골라서 하나의 배열로 선택이 가능하다.
print(landmarks.iloc[3,:].values)
['110276240_bec305da91.jpg' 42 140 45 161 51 180 61 200 73 220 89 238 108
255 129 268 155 268 180 261 203 244 222 224 238 199 247 172 248 144 245
116 241 87 39 114 45 102 57 97 72 96 87 99 120 91 136 78 155 70 178 66
199 71 108 114 111 132 115 150 118 168 107 180 116 182 127 182 138 177
147 171 57 134 65 127 77 122 92 125 80 130 68 134 143 111 155 103 167 100
182 101 170 107 158 109 98 207 107 199 120 193 131 193 142 188 162 185
184 187 168 206 151 218 139 222 127 223 113 219 103 206 122 203 133 201
144 197 180 189 147 204 136 208 125 209]현재 데이터는 한 행에 이미지 이름과 특징점 데이터 두가지 그룹으로 나누어서 처리하는 것이 좋으므로 다음과 같이 분리해서 관리할 수 있다.
image_names = landmarks.iloc[3,0]
landmark_points = landmarks.iloc[3,1:].values
print(image_names)
print(landmark_points)
110276240_bec305da91.jpg
[42 140 45 161 51 180 61 200 73 220 89 238 108 255 129 268 155 268 180 261
203 244 222 224 238 199 247 172 248 144 245 116 241 87 39 114 45 102 57
97 72 96 87 99 120 91 136 78 155 70 178 66 199 71 108 114 111 132 115 150
118 168 107 180 116 182 127 182 138 177 147 171 57 134 65 127 77 122 92
125 80 130 68 134 143 111 155 103 167 100 182 101 170 107 158 109 98 207
107 199 120 193 131 193 142 188 162 185 184 187 168 206 151 218 139 222
127 223 113 219 103 206 122 203 133 201 144 197 180 189 147 204 136 208
125 209]
참고문헌
https://datascienceschool.net/view-notebook/704731b41f794b8ea00768f5b0904512/
Data Science School
Data Science School is an open space!
datascienceschool.net
'Programming > python' 카테고리의 다른 글
| 파이썬 패키지 리스트(requirements.txt) 만들기 (0) | 2019.09.01 |
|---|---|
| 파이썬 *args, **kwargs 이해하기 (0) | 2019.06.29 |
| Kaggle API로 머신러닝 데이터 다운받기 (1) | 2019.06.17 |
| [python] localtime으로 로컬 시간 정보 만들기 (0) | 2019.05.30 |
| format 관련 자료 링크 (0) | 2019.05.29 |
- Total
- Today
- Yesterday
- 3d프린터
- 메이커
- docker
- Stable Diffusion
- 우분투
- WSL
- MicroBit
- git
- nodejs
- 단축키
- fablab
- Python
- nvidia
- Fusion360
- Streamlit
- vscode
- vvvv
- ssh
- opencv
- Maker
- CAD
- conda
- cura
- comfyUI
- 파이썬
- Linux
- Arduino
- ubuntu
- 한글
- tensorflow
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |